 |
|
 |
|
|
|
En este capitulo trataremos de ver los aspectos generales sobre la administración de nuestro sistema contemplando algunas configuraciones que se tendrán que hacer, tomando como base un sistema pequeño como el podremos encontrar en nuestro hogar o en una empresa con pocas maquinas interconectadas.
Empezaremos reforzando el concepto de la cuenta root para que se tengan en cuenta las posibilidades de esta y los alcances que podremos dar a los demás usuarios.
Luego veremos varias maneras para poder arrancar nuestro sistema ejemplificando tres métodos como lo es la utilización de un diskette, el uso del LILO o desde la aplicación para DOS LOADLIN.
Nuestro sistema tendrá que tener la posibilidad de imprimir y es por ello que ejemplificaremos dos métodos para imprimir. Uno en la maquina local y otro en una maquina remota.
Como todo sistema requerirá en algún punto que se instale un kernel nuevo o se actualice parte de este. Veremos aspectos generales sobre las actualizaciones necesarias para nuestro sistema.
8.1 Si no eres root no eres nadie:
A este punto sabemos que la cuenta raíz que tiene el nombre de usuario root es el más importante del sistema y además es quien tiene los privilegios más altos para interactuar con él.
También sabemos, y esto a fuerza de malas experiencia muchas veces, que el ser root requiere responsabilidades y el estar conciente de lo que se hace con este tipo de cuentas ya que muchas veces un error que se cometa será irreparable.8.1.1 La cuenta root y sus implicaciones
Los usuarios del sistema están bastante restringidos en lo que pueden realizar, ya sea con los archivos de otros usuario o archivos de sistema, ya que no tienen los permisos necesarios para poder modificarlos o borrarlos e incluso en muchos casos leerlos.
Todas estas limitaciones se terminan con la cuenta root ya que posee acceso a cada área del sistema pudiendo borrar, crear, modificar archivos de cualquier parte del sistema así como cambiar permisos y dueños de estos. Puede ejecutar cualquier programa y hasta incluso si se le ocurriese podría literalmente matar al sistema por completo.
Esto es así ya que es necesario que exista por lo menos una persona que pueda intervenir al sistema si es necesario y que tenga los privilegios adecuados para poder forzar al sistema a realizar algo.
La idea es que esta cuenta se utilice sobriamente, únicamente cuando es necesario y no en cualquier momento.
Para ejemplificar un hecho que seria peligroso si e fuerce root, si un usuario normal de le ocurriese borrar los archivos que se encuentran en el directorio /boot el sistema no lo dejaría, en cambio si es el root quien lo pide, lo que este en /boot desaparecerá muchas veces, de acuerdo a la configuración de GNU/Linux que se posea, cargándose al kernel completo con ellos.
Para evitar cualquier accidente al utilizar la cuenta root es recomendable los siguientes pasos a seguir:
1.Pensarlo dos veces antes de apretar la tecla ENTER en un comando que pueda causar algún daño. Por ejemplo si se esta borrando algún archivo de configuración releer la línea del comando completo.
2.No acostumbrarse a usar root. Cuando más confortable se encuentre uno trabajando con el usuario root, más seguro que se confundirán los privilegios con los de un usuario normal.
3.Usar siempre un marcador distinto para un usuario normal y el root. Esto ya viene por defecto en la mayoría de las distribuciones pero siempre esta bien repetirlo. Un signo $ o % representara al usuario normal y un # representara al root.
4.Conectarse como usuario root solo cuando sea absolutamente necesario. Y desconectarse tan pronto como se haya terminado el trabajo. Cuando menos se use la cuenta root, menos posibilidades de cometer un error habrá.
Existen personas que son verdaderos "hackers" de UNIX que utilizan la cuenta root para todo, pero hay que recordar dos cosas con respecto a esto. Lo primero que no estamos a esa altura de conocimiento sobre UNIX y segundo que estas personas en algún momento han hecho algo que les a hecho perder su información.La cuenta root es poderosa en el sistema, y ese poder es peligroso muchas veces para el resto de los usuarios del sistema.
La tendencia a la destrucción de un usuario con el poder de root es perjudicial para el resto del sistema ya que en sucesivas oportunidades se a sabido de casos en los que los administradores del sistema leen correo de otro usuarios o borran archivos sin avisar a nadie jugando con el sistema informático como si fuesen niños y no como verdaderos administradores.
Por ello se requiere cierto grado de madurez y responsabilidad además del conocimiento necesario para poder llegar a ser administrador de un sistema y es en nuestros sistemas que tendremos en el hogar o en la oficina con GNU/Linux donde tendremos que aprender a serlo.
8.1.2 Gestión de usuarios
El sistema mantiene una cierta cantidad de información acerca de cada usuario. Dicha información se resume a continuación.
nombre de usuario
El nombre de usuario es el identificador único dado a cada usuario del sistema. Ejemplos de nombres de usuario son sebas, nanci y mdw. Se pueden utilizar letras y dígitos junto a los caracteres "_" (subrayado) y "." (punto). Los nombres de usuario se limitan normalmente a 8 caracteres de longitud.
ClaveEl sistema también almacena la clave encriptada del usuario. El comando passwd se utiliza para poner y cambiar las claves de los usuarios.
user IDEl user ID, o UID, es un número único dado a cada usuario del sistema. El sistema normalmente mantiene la pista de la información por UID, no por nombre de usuario.
group IDEl group ID, o GID, es la identificación del grupo del usuario por defecto.
nombre completoEl nombre real" o nombre completo" del usuario se almacena junto con el nombre de usuario. Por ejemplo, el usuario schmoj puede tener el nombre "Jos Schmo" en la vida real.
directorio inicialEl directorio inicial es el directorio en el que se coloca inicialmente al usuario en tiempo de conexión. Cada usuario debe tener su propio directorio inicial, normal mente situado bajo /home.
intérprete de comandoEl intérprete de comando del usuario es el intérprete de comandos que es arrancado para el usuario en tiempo de conexión. Ejemplos pueden ser /bin/bash y /bin/tcsh.El fichero /etc/passwd contiene la información anterior acerca de los usuarios. Cada línea del fichero contiene información acerca de un único usuario; el formato de cada línea esnombre:clave encriptada:UID:GID:nombre completo:dir.inicio:intérprete
Un ejemplo puede ser:
sebas:Xv8Q981g71oKK:102:100:Sebastián Criado:/home/scrido:/bin/bash
Como puede verse, el primer campo , "sebas", es el nombre de usuario.
El siguiente campo, "Xv8Q981g71oKK", es la clave encriptada. Las claves no se almacenan en el sistema en ningún formato legible por el hombre. Las claves se encriptan utilizándose a sí mismas como clave secreta. En otras palabras, sólo si se conoce la clave, ésta puede ser desencriptada. Esta forma de encriptación es bastante segura.
Algunos sistemas utilizan "claves en sombra" (shadow) en la que la información de las claves se relega al fichero /etc/shadow. Puesto que /etc/passwd es legible por todo el mundo, /etc/shadow suministra un grado extra de seguridad, puesto que éste no lo es. Las claves en sombra suministran algunas otras funciones como puede ser la expiración de claves; no entraremos a detallar éstas funciones aquí.
El tercer campo "102", es el UID. Este debe ser único para cada usuario. El cuarto campo,"100", es el GID. Este usuario pertenece al grupo numerado 100. La información de grupos, como la información de usuarios, se almacena en el fichero /etc/group.
El quinto campo es el nombre completo del usuario. "Sebastián Criado". Los dos últimos campos son el directorio inicial del usuario (/home/sebas) y el intérprete de conexión (/bin/bash), respectivamente. No es necesario que el directorio inicial de un usuario tenga el mismo nombre que el del nombre de usuario. Sin embargo, ayuda a identificar el directorio.
Borrando usuarios
Anteriormente en él capitulo vimos como podríamos crear un usuario para empezar a utilizar el sistema, y este método puede emplearse para la creación de cualquier otro usuario.
De forma parecida, borrar usuarios puede hacerse con los comandos userdel o deluser dependiendo de qué software fuera instalado en el sistema.Si se desea "deshabilitar" temporalmente un usuario para que no se conecte al sistema (sin borrar la cuenta del usuario), se puede prefijar con un asterisco ("*") el campo de la clave en /etc/passwd.
Por ejemplo, cambiando la línea de /etc/passwd correspondiente a sebas a
sebas:*Xv8Q981g71oKK:102:100:Sebastián Criado:/home/sebas:/bin/bash
evitará que sebas se conecte.
Después de que haya creado un usuario, puede necesitar cambiar algún atributo de dicho usuario, como puede ser el directorio inicial o la clave. La forma más simple de hacer ésto es cambiar los valores directamente en /etc/passwd. Para poner clave a un usuario, utilice el comando passwd.
Por ejemplo,
[root@LUSI] # passwd nanci
cambiará la clave de nanci. Sólo root puede cambiar la clave de otro usuario de ésta forma. Los usuarios pueden cambiar su propia clave con passwd también.
En algunos sistemas, los comandos chfn y chsh están disponibles, permitiendo a los usuarios el cambiar sus atributos de nombre completo e intérprete de conexión. Si no, deben pedir al administrador de sistemas que los cambie por ellos.
Grupos
Como hemos citado anteriormente, cada usuario pertenece a uno o más grupos. La única importancia real de las relaciones de grupo es la perteneciente a los permisos de ficheros, como dijimos anteriormente cada fichero tiene un "grupo propietario" y un conjunto de permisos de grupo que define de qué forma pueden acceder al fichero los usuarios del grupo.
Hay varios grupos definidos en el sistema, como pueden ser bin, mail, y sys. Los usuarios no deben pertenecer a ninguno de estos grupos; se utilizan para permisos de ficheros del sistema. En su lugar, los usuarios deben pertenecer a un grupo individual, como users. Si se quiere ser detallista, se pueden mantener varios grupos de usuarios como por ejemplo estudiantes, soporte y facultad.
El fichero /etc/group contiene información acerca de los grupos. El formato de cada línea es
nombre de grupo:clave:GID:otros miembros
Algunos ejemplos de grupos pueden ser:
root:*:0:
usuarios:*:100:nanci,pedro
invitados:*:200:
otros:*:250:sebasEl primer grupo, root, es un grupo especial del sistema reservado para la cuenta root. El siguiente grupo, users, es para usuarios normales. Tiene un GID de 100. Los usuarios nanci y pedro tienen acceso a este grupo. Recuérdese que en /etc/passwd cada usuario tiene un GID por defecto. Sin embargo, los usuarios pueden pertenecer a mas de un grupo, añadiendo sus nombres de usuario a otras líneas de grupo en /etc/group. El comando groups lista a qué grupos se tiene acceso.
El tercer grupo, invitados, es para usuarios invitados, y otros es para "otros" usuarios. El usuario sebas tiene acceso a éste grupo.
Como se puede ver, el campo "clave" de /etc/group raramente se utiliza. A veces se utiliza para dar una clave para acceder a un grupo. Esto es raras veces necesario. Para evitar el que los usuarios cambien a grupos privilegiados (con el comando newgroup), se pone el campo de la clave a "*".
Se pueden usar los comandos addgroup o groupadd para añadir grupos a su sistema. Nor malmente es más sencillo añadir líneas a /etc/group uno mismo, puesto que no se necesitan más configuraciones para añadir un grupo. Para borrar un grupo, sólo hay que borrar su entrada de /etc/group.
8.1.3 Poniendo reglas al sistema
El S.O. UNIX no fue diseñado desde sus principios pensando en la seguridad entre los usarios del sistema. El pensar que usarios academicos irrumpieran en areas que no les pertenecian no se tomaba en como algo posible para los primeros tiempos en que UNIX estaba desarrollandoce.
El tener una actitudde mano dura con los usarios no ayudara a que estos traten de saltarce las limitaciones que le podamos haber impuesto.Puede ser que en un ambiente militar esto fucnione pero no sera igual en un sistema universitario o en una empresa.
Lo que si tiene sentido es el escribir una serie sencillas de reglas que el usario pueda seguir y que tienen que ir de acuerdo a las politicas del area donde se esta implementando el sitema informatico.
Puede darce el caso de que existan reglas que esten en contra de las politicas o que no eten bien explicadas por lo que sera dificil de cumplir.
También esta el caso de que si las reglas son por demas de restrictivas con el usario este tratara de saltarcelas.
Otro caso serian los usarios que por desconocimiento de estas reglas realizan acciones prohibidas.
Por ejemplo, envian mails de 20 MB por la red saturando la conección dado que no se especifica claramente que no pueden mandarce mails con atach tan grandes. Si nadie se lo informa al usuario no podemos pedirle que obedezca.
Los motivos por los cuales las reglas se implementan deveran estar claros, ya que los usuarios se sentiran tentados a hacer cosas que estan prohibidas por que si, sin ninguna otra esplicación.
8.2 Iniciando el sistema
Nuestro sistema GNU/Linux tiene varias formas de ser iniciado bien sea desde floppy disk o desde el disco rigido:
Utilizando un floppy disk de arranque
Mucha gente arranca Linux utilizando un "floppy disk de arranque" que contiene una copia del núcleo de Linux. A este núcleo se le indica la partición raíz de Linux para que sepa donde buscar en el disco rígido el sistema de ficheros raíz. (El comando rdev puede ser utilizado para poner la partición raíz en la imagen del núcleo) Por ejemplo, este es el tipo de floppy creado por Slackware durante la instalación.
Para crear su propio disquete de arranque, localicemos en primer lugar la imagen del núcleo en su disco duro. Debe estar en el fichero /boot o /. Algunas instalaciones utilizan el fichero /vmlinux para el núcleo.
En su lugar, puede que tenga un núcleo comprimido. Un núcleo comprimido se descomprime asimismo en memoria en tiempo de arranque, y utiliza mucho menos espacio en el disco duro. Si se tiene un núcleo comprimido, puede encontrarse en el fichero /boot/zImage o /zImage. Algunas instalaciones utilizan el fichero /vmlinuz para el núcleo comprimido.
Una vez que se sabe donde está el núcleo, podemos usar el comando mkbootdisk con el que podremos hacer un disco de arranque:
[root@LUSI]# mkbootdisk --device /dev/fd0 2.2.14
Donde 2.2.14 es el nombre del núcleo que actualmente esta corriendo.
De esta forma se creara un sistema de archivos en el floppy que contendrá la imagen del kernel y los módulos necesarios para funcionar.
Este floppy debe arrancar ahora Linux.
8.2.2 Utilizando LILO
Otro método de arranque es utilizar LILO, un programa que reside en el sector de arranque del disco duro. Este programa se ejecuta cuando el sistema se inicia desde el disco duro, y puede arrancar automáticamente Linux desde una imagen de núcleo almacenada en el propio disco duro.
LILO puede utilizarse también como una primera etapa de carga de varios sistemas operativos, permitiendo seleccionar en tiempo de arranque qué sistema operativo (como GNU/Linux o MS-DOS) arrancar. Cuando se arranca utilizando LILO, se inicia el sistema operativo por defecto, a menos que pulse TAB durante la secuencia de arranque. Si se pulsa esta tecla, se le presentará un indicador de arranque, donde debe teclear el nombre del sistema operativo a arrancar (como puede ser "linux" o "msdos").
La forma más simple de instalar LILO es editar el fichero de configuración, /etc/lilo.conf, y ejecutar el comando:
[root@LUSI] # /sbin/lilo
El fichero de configuración de LILO contiene una "estrofa" para cada sistema operativo que se pueda querer arrancar. La mejor forma de mostrarlo es con un ejemplo de un fichero de configuración LILO. El ejemplo siguiente es para un sistema que tiene una partición raíz Linux en /dev/hda2 y una partición Windows en /dev/hda1.
# Le indicamos a LILO que modifique el registro de arranque de
# /dev/hda (el primer disco duro no-SCSI). Si se quiere arrancar desde
# una unidad distinta de /dev/hda, se debe cambiar la siguiente línea
boot = /dev/hda
default=linux# Nombre del cargador de arranque. No hay razón para cambiarlo, a menos
# que se esta haciendo una modificación será del LILOinstall = /boot/boot.b
# Estrofa para la partición raíz de Linux en /dev/hda2.
image = /boot/2.2.14 # Ubicación del kernel
label = linux # Nombre del SO (para el men de arranque de LILO)
root = /dev/hda2 # Ubicación de la partición raíz
vga = ask # Indicar al núcleo que pregunte por modos SVGA
# en tiempo de arranque
# Estrofa para la partición Windows en /dev/hda1.
other = /dev/hda1 # Ubicación de la partición
table = /dev/hda # Ubicación de la tabla de partición para #/dev/hda2
label = W$ # Nombre del SO (para el men de arranque)
La línea default indica la etiqueta del sistema operativo que arrancará LILO por defecto. Se puede seleccionar otro sistema operativo en el indicador de arranque de LILO, tal y como se indicó anteriormente.
Recuerde que cada vez que actualice la imagen del núcleo en disco, se debe reejecutar /sbin/lilo para que los cambios queden reflejados en el sector de arranque de su unidad.
Utilizando LOADLIN:
Anteriormente el sistema de arranque que utilizaba al LILO tenia un problema. Este era que el kernel no podía estar mas allá del cilindro 1024 dado que no se cargaría.
A partir de las nuevas versiones de LILO esto se esta solucionando.
De esta forma la única manera que nos quedaba para iniciar GNU/Linux era a trabes de un disquete con la subsiguiente lentitud que esto tenia.
Por esto se desarrollo una aplicación que permitía que arrancáramos el núcleos del sistema desde una partición DOS.
Esta aplicación se denomina LOADLIN y lo que hace es sencillo.
En un directorio de la partición DOS se guarda el kernel y a partir de el comando loadlin se le indica el kernel que se quiere cargar y la partición donde se encuentra GNU/Linux instalado.Ej: loadlin c:\vmlinuz root=/dev/hdb2 ro
De esta forma se saldrá de DOS/WINDOWS y se cargara el kernel en memoria.
8.3 Acerca de impresoras:
Extraído del Printer Ho-To de Grant Taylor gtaylor@cs.tufts.edu y Brian McCauley B.A.McCauley@bham.ac.uk
Todo sistema que se precie es capaz de gestionar una o varias impresoras, con uno o varios usuarios, que les envían distintas clases de documentos, más o menos dignamente.
Unix resuelve estos problemas mediante un conjunto de programas, los servidores de impresión, que gestionan los trabajos pendientes, y los encauzan a las impresoras adecuadas, todo de manera completamente transparente al usuario.
El camino más corto en UNIX (y bajo Linux), es enviar los datos a imprimir directamente al dispositivo adecuado. El siguiente comando envía un listado del directorio a la primera impresora en paralelo (hablando en DOS, LPT1:):[root@LUSI]# ls > /dev/lp1
El problema de este método es que no aprovecha las capacidades de multitarea de Linux, debido a que el tiempo que tarda el comando en completarse será el mismo que emplee la impresora en despachar el trabajo.
En una impresora lenta, o en una apagada o sin papel, puede prolongarse un poco. Podríamos ejecutar el comando simplemente en segundo plano, pero no adelantaríamos mucho. Además, deberá tener privilegios de root.
Un remedio mejor es crear un área de spool, es decir, guardar los datos a imprimir en un fichero temporal, y arrancar un proceso en segundo plano que envíe los datos a la impresora, y gestione las incidencias que se presenten.
Esencialmente, así funciona Linux. Para cada impresora, se define un área spool, donde cada trabajo pendiente se almacena en un fichero. Un proceso en segundo plano (llamado el demonio de impresión) analiza metódica y constantemente los ficheros spool, buscando nuevos datos a imprimir. Cuando aparece alguno, son enviados a la impresora apropiada; cuando más de un fichero está a la espera, se colocan en una cola (el primero que entra es el primero que se procesa), por lo que se habla propiamente de la "cola de impresión".
En el caso de impresión remota, los trabajos se gestionan localmente, como cualquier otro, pero el demonio de impresión lo envía a través de la red hacia el ordenador o impresora destino.
La información que el demonio de impresión necesita para su trabajo (el dispositivo físico, el spool de datos, la máquina e impresora remota ...) se almacenan en un fichero llamado "printcap", que describiremos más tarde.
En lo sucesivo, el término "impresora" se referirá a una máquina lógica definida en /etc/printcap. El concepto "impresora física", define la cosa que mancha papel. Es perfectamente posible describir múltiples entradas en /etc/printcap que se refieren a una sola impresora física, pero por caminos tortuosos. No nos preocupemos, lo aclararemos al describir printcap.8.3.1 Lo primero a tener en cuenta
El sistema de impresión de Linux se sustenta en cinco programas, que deberían estar donde aparecen en el siguiente listado, propiedad de root, y grupo lp (o daemon, según el sistema en concreto):
-rwxr-xr-x root lp /bin/lpr-rwxr-xr-x root lp /bin/lpq
-rwxr-xr-x root lp /bin/lpc
-rwxr-xr-x root lp /bin/lprm
-rwxr-x--- root lp /sbin/lpd
Los cuatro primeros tienen por fin enviar, cancelar y examinar los trabajos de impresión. /sbin/lpd es el demonio de impresión.OJO: Los directorios, permisos y propiedad de los ficheros pueden diferir a los de su sistema, aunque no deberían ser MUY distintos.
Hay páginas de manual que explican con detalle todas estas órdenes y que debería consultar para ampliar información.
Es importante saber que, por defecto, lpr, lprm, lpc y lpq trabajan con una impresora llamada "lp". Si define la variable de entorno PRINTER con el nombre de una impresora, pasará a ocupar el valor por defecto. Se puede indicar sobre la marcha una impresora distinta con la opción -P impresora en la línea de órdenes.
8.3.2 Los directorios fundamentales.
Realmente, sólo hay un directorio importante: el área de spool donde se almacenan los datos a la espera de que lpd decida qué hacer con ellos. Sin embargo, un sistema típico debería configurarse en varios directorios, uno para cada impresora, lo que facilita notablemente el mantenimiento. En la mayoría de las instalaciones, /var/spool/lpd es el directorio spool principal, y cada impresora tiene un subdirectorio particular, con el mismo nombre que la impresora. Así, si tiene una impresora llamada PJL-16 que admite PostScript y HPGL, debería crear dos directorios, por ejemplo /var/spool/lpd/PJL-16-ps y /var/spool/lpd/PJL-16-hpgl.
Los directorios temporales deberían pertenecer a root, grupo lp; user y group deben poder leer y escribir, y el resto, leer. permisos: -rwxrwxr-x (775)Para cada directorio de impresora, la orden adecuada sería:
[root@LUSI]# chmod ug=rwx,o=rx PJL-16-ps
[root@LUSI]# chgrp lp myprinterLos destinos, permisos y propietarios aquí indicados deben considerarse como indicativos, pues pueden variar entre distintos sistemas e instalaciones.
Y sus correspondientes ficheros.
Además de los programas ya tratados, cada directorio temporal debe contener como mínimo estos cuatro ficheros: ".seq" , "errs" , "lock" y "status". Deberán tener permisos : -rw-rw-r-- (664).El fichero .seq contiene la secuencia de trabajos enviados. status contiene el mensaje que devuelve "lpc stat". El fichero lock impide al lpd imprimir al tiempo dos trabajos en la misma impresora, y errs guarda un registro de los fallos de la impresora.
El fichero "errs" es actualmente potestativo, y ahora puede llamarse como le apetezca su nombre se especificará en /etc/printcap. Debe, sin embargo, existir un fichero que permita a lpd registrar los mensajes de error.8.3.3 /etc/printcap
/etc/printcap es un fichero texto, modificable con su editor favorito.
Su propietario debe ser root y debe tener permisos: -rw-r--r-- (644)
Aunque a golpe de vista parezca tan comprensible como la piedra Rosetta , su estructura es muy sencilla y asequible. Parte de la mala fama se debe a que algunas distribuciones no incluyen página de manual para printcap, y el hecho de que muchos printcap están generados por programas, o por gente cuya manera de despreciar al género humano es omitir comentarios que ayuden a su compresión. Desde aquí hacemos un llamamiento para que su fichero printcap sea tan legible como sea posible.
Cada entrada de printcap describe una impresora. Mejor aún, cada entrada de printcap provee una denominación lógica para un dispositivo físico, y describe cómo deben los datos ser enviados y manejados por él.
Por ejemplo, una entrada de printcap definirá qué puerto vamos a usar, qué directorio spool, qué proceso deben soportar los datos, qué clase de errores debemos notificar, qué volumen de datos se permiten enviar como máximo, o limitar el acceso de ciertos dispositivos.
Además, podemos definir distintos modos de procesar datos para una misma impresora. Por ejemplo, una misma impresora de HP puede manejar datos en formatos PostScript, HPGL y PCL, dependiendo de la secuencia de órdenes que le enviamos al comienzo de cada trabajo. Tendría sentido definir los tres modos de trabajo como sendas impresoras, cada una de las cuales procesará los datos dependiendo del modo de trabajo. Los programas que generan datos ps se enviarán a la impresora PS, los dibujos HPGL a la impresora HPGL, y así sucesivamente.
Llamaremos "filtros" a los programas que procesan los datos a imprimir. Un filtro puede incluso no enviar ningún dato al puerto.
Los campos de /etc/printcap.
Un ejemplo típico de entrada en /etc/printcap podría ser:
# Ejemplo de printcap con dos alias impresora|HP850C:\
# lp es el dispositivo de impresión, en este caso, la primera impresora
:lp=/dev/lp1:\
# sd indica el directorio spool
:sd=/var/spool/lpd/HP850C:
Como vemos, cada entrada de /etc/printcap se estructura en una serie de campos, encabezados por una etiqueta, y limitados por dos puntos, a excepción del primer campo, que describe la impresora. Los campos pueden tener tres tipos de valores - Texto, lógico y numérico, en los que nos extenderemos más adelante.
La primera línea de la entrada determina el nombre y alias de la impresora. La impresora por defecto debería llamarse "lp"; por ejemplo, si la impresora del ejemplo anterior es la única que tenemos, la primera línea sería:# Ejemplo para la impresora por defecto
lp|HP850C:\Podemos usar el nombre que nos apetezca como "La Picadora de papel del despacho de Gertrudis", aunque no parezca quizá muy práctico. Ojo: Sólo podemos tener una impresora llamada "lp".
Los siguientes campos son los más comunes, y los más importantes:
Campo Tipo Descripción

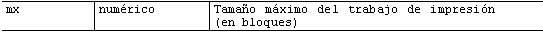
· lp apunta al puerto/dispositivo de impresión. Si especificamos /dev/null como dispositivo, el resto de los procesos se ejecutan normalmente, pero los datos de salida van a parar al inodoro. No se utiliza a excepción de las pruebas de configuración del dispositivo. Cuando configure una impresora remota con los campos rm y rp , debería poner ":lp=:" en /etc/printcap, indicando que no está asignada a ningún dispositivo local.. No deje este campo en blanco a menos que use una impresora remota, o el demonio de impresión se quejará amargamente, si no especifica un dispositivo de impresión.· lf guarda un registro de los errores de impresión. Cualquier fichero que especifique deberá existir antes de su uso, o no se registrarán las incidencias.
· if indica el nombre del filtro de impresión a ejecutar. Los filtros son programas que reciben datos por la entrada estándar, y los devuelven procesados por la salida estándar. Un empleo típico es detectar texto llano y convertirlo en PostScript para imprimirlo en ese tipo de trastos. Son muy útiles, por ejemplo, para eliminar el efecto escalera, o cambiar la página de códigos sin necesidad de cambiar la configuración de la impresora cada vez que la usemos entre UNIX y DOS. Cuando se especifica un filtro de entrada, el demonio de impresión no envía los datos pendientes al dispositivo especificado. En su lugar, arranca el filtro y asigna el fichero temporal a la entrada estándar, y el dispositivo de impresión como salida estándar.Probemos /etc/printcap con un ejemplo:· rm y rp controlan el destino de la impresión remota. Enviar el documento a imprimir a una impresora remota es tan fácil como indicar el anfitrión en rm, la impresora correspondiente en rp, y asegurarse que lp está vacío. Fíjese en que los datos se tamponan localmente antes de ser enviados, y que le ejecutará cualquier filtro que especifique. Una entrada típica de /etc/printcap en la máquina local (pera.huerta.net) para trabajar sobre la impresora picapapel, en la estación rábano.huerta.net (remota), sería: picapapel:lp=:rm=rábano.huerta.net:rp=picapapel:sd=/var/spool/lpd/picapapel: En la máquina remota necesitará que /etc/hosts.equiv o /etc/hosts.lpd contenga la línea pera.huerta.net; Tenga cuidado con los permisos de acceso.
· sh y sf: Portadillas y separadores. Salvo que haya mucha gente distinta usando su impresora, probablemente no estará interesado en las páginas separadoras de trabajos. Las páginas de fin de trabajo son particularmente molestas cuando se trabaja con procesadores de texto, que componen páginas completas, por lo que si especificamos sf, tendremos al final de cada trabajo una página en blanco. sf es muy útil, sin embargo, si usamos la impresora para listar directorios, ficheros en crudo ..., asegurándonos que el trabajo sale completo de la impresión. Se puede presentar un problema si tenemos una impresora PostScript, al quedar residente el último tipo de letra utilizado. Con el campo :tr: lo evitaremos. Es preferible en estos casos dejar :sh:, y que sean los filtros quienes se encarguen de generar las portadillas.
· mx limita el tamaño del spool de datos, señalando una cantidad en bloques de 1 K ( 1024 bits ). Si mx=0, el límite viene dado por el espacio disponible en disco. Recuerde que lo que limitamos es el tamaño del spool, no la cantidad de datos impresos. Si intentamos sobrepasar el límite, el fichero simplemente se trunca, y el usuario recibe el mensaje
· lpr: fichero: copy file is too large".· mx es útil si tiene programas que accidentalmente pueden generar un volumen desproporcionado de datos a imprimir (imágenes, por ejemplo); para impresoras ps, no suele tener mucho interés, pues un volumen pequeño de datos en formato ps pueden generar una notable cantidad de papel impreso. Podemos sustituir el límite de mx escribiendo en cada directorio spool un fichero llamado "minfree" que contiene el espacio mínimo disponible que permita aceptar trabajos, en forma de fichero texto con el número de bloques mínimos disponibles. Normalmente, suele ser un enlace con el original en /var/spool/lpd, ya que es inusual que cada impresora deba tener un mínimo diferente.
El siguiente guión de shell es un filtro de entrada muy simple. Sólo encadena su entrada al final de un fichero en /tmp, tras una pancarta adecuada. Usaremos este filtro en el campo if, y enviaremos los datos a /dev/null, ahorrándonos las quejas del demonio especificando un dispositivo de impresión.#!/bin/sh
# Este filtro debera colocarse en el directorio tampon, con el nombre
# filtro_entrada, propiedad de root, grupo lp y permisos -rwxr-xr-x
#
echo ------------------------------------------------>/tmp/testlp.out
date >> /tmp/testlp.out
echo ------------------------------------------------>>/tmp/testlp.out
catY aquí tenemos nuestra flamante entrada en /etc/printcap. Vea que el formato es razonablemente inteligible, usando caracteres de continuación de línea "\" al final de cada una, excepto la última (de hecho, cada entrada en /etc/printcap es una sola línea):
impre|PLJ-H1998:\
:lp=/dev/null:\
:sd=/var/spool/lpd/PLJ-H1998:\
:lf=/var/spool/lpd/PLJ-H1998/errores:\
:if=/var/spool/lpd/PLJ-H1998/filtro_entrada:\
:mx#0:\
:sh:\
:sf:Ojo: NO DEJE ESPACIOS EN BLANCO, o no funcionará (le aparecerán impresoras sin nombre, no logrará volcar los trabajos, y se acumularán en cola generosamente)
Ahora que trabaje:
· Primero: DEBE SER EL SUPERUSUARIO (root), tanto si le gusta como si no.
· Segundo: Compruebe los permisos y situaciones de lpr, lprm, lpc, lpq y lpd.
· Tercero: Cree el directorio spool de su impresora: (recuerde que el propietario debe ser root, el grupo lp, y los permisos -rwxrwxr-x con las órdenes:
o mkdir /var/spool/lpd /var/spool/lpd/impre· Cuarto: En el directorio spool cree los ficheros necesarios, con los debidos permisos y propietarios:
o chown root.lp /var/spool/lpd /var/spool/lpd/impre
o chmod ug=rwx,o=rx /var/spool/lpd /var/spool/lpd/impreo cd /var/spool/lpd/impre· Quinto: Cree el script filtro de entrada en el directorio spool. Use por ahora el filtro de prueba anterior. Asegúrese que el fichero pertenece a root.lp, y es ejecutable para todos.
o touch .seq errores status lock
o chown root.lp .seq errs status lock
o chmod ug=rw,o=r .seq errs status lock· Sexto: Cree el fichero /etc/printcap tal y como lo hemos descrito en el punto anterior. Su propietario será root y sus permisos -rw-r--r--.
· Séptimo: Compruebe que rc.local (normalmente en /etc/rc.d/) contiene la línea /sbin/lpd, y añádala si no está. Esto hace que arranque el demonio de impresión al arrancar. De todos modos puede arrancarlo a mano con la orden lpd.
· Octavo: Haga una prueba: cruce los dedos y teclee
o ls -l | lpr -Pimpre· Noveno: Busque en /tmp un fichero llamado testlp.out. Debería contener un listado del directorio, con un encabezado.· Décimo: Si ha funcionado (y no dudamos que habrá sido así), edite /etc/printcap, y copie la entrada de prueba en el mismo fichero; En la primera entrada, cambie el nombre de la impresora a "testlp", o el que usted prefiera, pero que no use como nombre real de impresora. En la segunda entrada (que ahora será la de su impresora real), cambie el contenido de lp=/dev/null al del puerto de impresora (normalmente será /dev/lp1) de su ordenador, salvo que vaya a utilizar una impresora remota, en cuyo caso deberá definir rm y rp. Cambie el nombre del filtro if si tiene ya uno previsto, o suprímalo si no va a utilizar ninguno.
· Once: Reinicie el sistema, o mate el demonio de impresión y arránquelo, ya que lpd sólo lee /etc/printcap al comenzar su trabajo.
· Doce: Haga una prueba, y aprecie lo bien que funciona su impresora (Si tiene problemas con el efecto escalera, siga leyendo).
Para añadir nuevas impresoras, sólo tendrá que repetir la entrada de printcap, con las modificaciones pertinentes a cada dispositivo.8.3.1 Impresión remota e impresión local.
La impresión remota nos permite enviar trabajos de impresión desde una máquina, hacia otra (computadora/impresora) conectada a una red; por ejemplo, nuestro equipo funciona de servidor en una red, o si una impresora asignada a nuestra máquina debe ser accesible por otros ordenadores.
Imprimimos localmente cuando usuarios de nuestra máquina envían trabajos a una impresora conectada directamente a la misma.Como primer paso, cualquier máquina que intente imprimir en su sistema, debe estar registrada en cualquiera de los ficheros /etc/hosts.equiv o /etc/hosts.lpd, que son simples ficheros de texto, con un nombre de maquina por línea. Es preferible el segundo, reservando el primero para proporcionar mayores permisos de acceso, lo que debería ser evitado en lo posible.
Puede restringirse el uso tanto por nombre como por grupos. Especifique los grupos autorizados con uno o varios campos ":rg:" en /etc/printcap - :rg=admin: sólo autorizará el acceso a la impresora a los usuarios asignados al grupo admin. Puede también limitar el acceso a aquellos usuarios con cuenta en su sistema utilizando el campo lógico :rs:.
La configuración en el sistema cliente seria la siguiente:lp|Remote printer entry:\
:lp=/dev/null
:rm=192.168.1.1 #Aquí puede ir también el nombre del #servidor de impresión.
:rp=lp:\
:sd=/var/spool/lpd/remote:\
:mx#0:\
:sh:8.4 Actualización del sistema
Una tarea que es muy importante para el administrador es la de mantener actualizado el sistema y la instalación de nuevo software en el.
Dado que el mundo de GNU/Linux se mueve muy rápidamente se tendrán que tener los recaudos necesarios para que el sistema que se esta administrando no quede pronto obsoleto. Ahora esto no hay que confundirlo con que se tenga que estar pendiente de todo lo que cambia en nuestro sistema, ya que si así lo hiciéramos nos la pasásemos mas tiempo actualizándolo que usándolo.
Mucha gente siente la necesidad de actualizar el sistema cada vez que una versión nueva de la distribución que se esta usando sale, pero esto también es una perdida de tiempo ya que no todo el sistema cambia por lo que no se justifica la compra de una nueva distribución o el bajarse los 6 discos que la componen. Por esto, la mejor forma de realizar una actualización del sistema es haciéndola a mano, lo que trataremos de ver con unos puntos clave del sistema como lo son el kernel, las bibliotecas y el software esencial para el funcionamiento optimo del sistema.Actualizando el Núcleo:
La actualización del núcleo o kernel del sistema no es bajarse el código fuente de este y realizar una compilación. Esto permite habilitar ciertas funciones que no vienen en los kernel pre-compilados o puede desactivar otras que no son necesarias.
Los fuentes del kernel se pueden obtener de numerosos sitios de ftp. El mas conocido es el de kernel.org cuya pagina es http://www.kernel.org y el ftp es ftp://ftp.kernel.org . Los kernel se encuentran indexados por el numero de la versión (ej v2.2) donde se encontraran los sucesivos niveles de parche de cada versión (ej 2.2 parche 16 seria 2.2.16)
El kenel vendrá comprimido en dos formas posibles, tar.gz y tar.bz2, este ultimo sistema de compactación es mucho mas eficiente que gz.
El método para descomprimirlos es el habitual, se recomienda la lectura de las paginas de manual de cada uno de los métodos de compactación para efectuarlo.
Se deberá realizar la descompresión en el directorio /usr/src donde se creara un directorio con el nombre de la versión del kernel y su nivel de parche. Existe un enlace que estará apuntando a los fuentes del kernel anterior denominado linux. Este enlace deberá cambiarse para que apunte al código del kernel nuevo.[root@LUSI]# ln -sf /usr/src/2.2.16 /usr/src/Linux
Hay que tener en cuenta que para realizar la compilación del kernel se deberá contar con los compiladores necesarios. Estos son el gcc y el g++ que son los compiladores de C y C++ que deberán estar instalados en el sistema. Mas adelante veremos como podremos tener una versión reciente de estos.
Una ves que nos sesionamos que tenemos todo lo necesario se procederá a ejecutar el programa de configuración del kernel. Existen 3 formas de realizar esto: La primera y menos recomendable es el ejecutar en el directorio /usr/src/linux la sentencia "make config" que correrá un script que nos preguntaran uno a uno todos los aspectos del kernel. Esta forma es por demás de tediosa y no la veremos aquí.
Otra forma es realizarlo a través de un front-end grafico realizando un "make xconfig" con lo que tendremos una vista bastante cómoda para efectuar la configuración. El problema que puede presentarse aquí es que no se cuente con los paquetes de desarrollo del lenguaje Tk que se utilizan para el programa en X por lo que posiblemente no funcione en algunos sistemas.
Una tercer forma es la de ejecutar "make menuconfig" que nos levantara un programa de configuración pero de consola y es la forma que funciona de forma más cómoda.
La sugerencia es que se tome como punto de partida la configuración del kernel anterior. Esta puede tomarse al haberse guardado en un archivo que podrá tener un nombre como "configuración.kernel.fecha" o el que se les ocurra. SI no lo tienen lo pueden generar a partir del programa de configuración del kernel anterior solicitándole que guarde la configuración en un archivo. Opción que aparece en la parte inferior de la ventana de configuración en el menuconfig. Ahora se puede tomar con la opción de carga de configuración del kernel nuevo, la configuración anterior y modificarla según nuestros requerimientos.
Una ves realizado los cambios de configuración necesarios se recomienda el guardar la configuración en un archivo, además de en el mismo kernel, para futuros cambios.Cuando se termina de configurar, se le instará al ejecutar `make dep' y `make clean'. Al hacer `make dep' se prepararán las dependencias necesarias para efectuar la compilación. Cuando acabe, hay que hacer un `make clean'. Esto elimina ficheros objetos y demás de la versión anterior. No olvidar este paso.
Después de preparar dependencias, puede ejecutar `make zImage' o `make zdisk' (esta es la parte que tarda más tiempo). `make zImage' compilará el núcleo y lo dejará comprimido en arch/i386/boot/zImage junto a otros ficheros. Con `make zdisk' el nuevo núcleo se copiará además en el disquete que esté puesto en la disquetera ``A:''. `zdisk' es interesante para probar núcleos; si explota (o simplemente no hace nada) se quita el disquete de la disquetera y se podrá arrancar el núcleo antiguo. Además sirve para arrancar si se borró accidentalmente el núcleo del disco duro.
Otra opción es efectuar la compactación del kernel con un método mas eficiente dado que el LILO se pone nervioso con kernel muy grandes. Por esto se podrá efectuar un 'make bzImage' lo que compactara aún mas el kernel. Un núcleo comprimido se descomprime automáticamente al ser ejecutado.
Una vez que se tenga un nuevo núcleo que parezca funcionar como desea, será el momento de instalarlo. Casi todo el mundo utiliza LILO (LInux LOader) para esto.
Una forma muy cómoda de llevar todo el tema del LILO, si lo tenemos instalado, y las compilaciones, etc, es añadir lo siguiente en el /etc/lilo.conf:
...
image=/vmlinuz
label=ultimo
root=/dev/hd[loquesea]
read-only
append = ""
image=/vmlinuz.old
label=anterior
root=/dev/hd[loquesea]
read-only
append = ""Al compilar, si lo hacemos con la secuencia de comandos
[root@LUSI]# make dep
[root@LUSI]# make clean
[root@LUSI]# make zlilo
[root@LUSI]# make modules
[root@LUSI]# make modules_installel make zlilo renombrará la anterior imagen del kernel a /vmlinuz.old , dejando la nueva como /vmlinuz, e instalará LILO, a continuación con lo cual lo hacemos todo automáticamente.
La órdenes make modules; make modules_install compilarán los módulos que hayamos seleccionado, y los instalarán. No hay olvidar ejecutar depmod -a en cuanto hayamos arrancado con dicho núcleo.
En caso de que estemos compilando por segunda vez una misma versión de núcleo, y hayamos variado el número de módulos a compilar, es posible que la ejecutar make dep nos encontremos con un mensaje de error; esto se debe a que los antiguos módulos que no hayamos compilado ahora no son borrados. Pueden borrarse tranquilamente.Actualizando las bibliotecas:
La mayor parte del software de GNU/Linux esta compilado para que utilice bibliotecas compartidas, por esto muchas veces se requieren juego de bibliotecas mas recientes para un determinado programa.
Las bibliotecas son compatibles en forma ascendente, es decir que un programa compilado para una versión antigua de bibliotecas funcionara igual con una versión mas reciente de las mismas pero lo contrario no se aplicara.
Las ultimas versiones de las bibliotecas de GNU/Linux puede encontrarse en los servidores de ftp://ftp.suncite.unc.edu. Los archivos de "versión" que se encuentran allí deberán explicar el proceso de instalación.
Se deben bajar los ficheros image-versión.tar.gz y inc-versión.tar.gz donde versión es la versión de las bibliotecas a instalar, por ejemplo 4.4.1. Son ficheros tar comprimidos con gzip; el fichero image contiene las imágenes de las bibliotecas a instalar en /lib y /usr/lib. El fichero inc contiene los ficheros de inclusión a instalar en /usr/include.El fichero release-versión.tar.gz debe explicar el método de instalación detalladamente (las
instrucciones exactas varían para cada versión). En general, se necesita instalar los ficheros de
bibliotecas .a y .sa en /usr/lib. Estas son las bibliotecas utilizadas en tiempo de compilación.Además, los ficheros imagen de las bibliotecas compartidas libc.so.versión se instalan en /lib.
Estas son las imágenes de las bibliotecas compartidas que son cargadas en tiempo de ejecución por los programas que utilizan las bibliotecas. Cada biblioteca tiene un enlace simbólico utilizando el número de versión mayor de la librería en /libPor ejemplo, la versión 4.4.1 de la librería libc tiene un número de versión mayor de 4. El fichero que contiene la librería es libc.so.4.4.1. Existe un enlace simbólico del nombre libc.so.4 en
/lib apuntando a este fichero. Por ejemplo, cuando se actualiza de libc.so.4.4 a libc.so.4.4.1,
necesita cambiar el enlace simbólico para apuntar a la nueva versión.
Es muy importante que se cambie el enlace simbólico en un solo paso, como se indica más abajo.
Si de alguna forma borrase el enlace simbólico libc.so.4, los programas que dependen del enlace
(incluyendo utilidades básicas como ls y cat) dejarán de funcionar. Utilice el siguiente comando
para actualizar el enlace simbólico libc.so.4 para que apunte al fichero libc.so.4.4.1:
[root@LUSI]# ln -sf /lib/libc.so.4.4.1 /lib/libc.so.4
Se necesita también cambiar el enlace simbólico libm.so.versión de la misma forma. Si se está actualizando a una versión diferente de las bibliotecas, sustituya lo anterior con los nombres adecuados.
La nota de la versión de la librería debe explicar los detalles. (Ver sección 3.10 para más información acerca de los enlaces simbólicos).
Actualizando gcc
El compilador de C y C++ gcc se utiliza para compilar software en su sistema, siendo el más importante el núcleo. La versión más reciente de gcc se encuentra en los servidores FTP de Linux.
En sunsite.unc.edu se encuentra en el directorio /pub/Linux/GCC (junto con las bibliotecas). Debe existir un fichero release para la distribución gcc detallando qué ficheros se necesitan obtener y como instalarlos
Sebastian D. criado - seba_AT_lugro.org.ar
www.lugro.org.ar

