 |
|
 |
|
|
|
Tema 1
Introducción a los Sistemas
Operativos
Información General:Un Sistema Operativo (SO) es una colección organizada de extensiones de software del hardware, consiente en rutinas de control que hacen funcionar una computadora y proporcionan un entorno para la ejecución de los programas. Existen otros programas que se apoyan en el SO para poder acceder a los recursos que necesitan. Esto se lleva a cabo a través de llamadas sistema operativo. También el SO debe brindar una forma de que el usuario se pueda comunicar con él a través de una interfaz que le brinde una vía de comunicación con el hardware del sistema informático.
El objetivo principal del SO es lograr que el sistema informático se use de manera cómoda, y el objetivo secundario es el lograr que el hardware de la computadora se emplee de modo eficiente.
El SO debe asegurar el correcto funcionamiento del sistema informático. Para lograr esto el hardware debe brindar algún mecanismo apropiado que impida que los usuarios intervengan en el funcionamiento del sistema y así mismo el SO debe poder utilizar este recurso de hardware de modo que esto se cumpla.
El SO debe ofrecer servicios a los programas y sus usuarios para facilitar la tarea de programación.
1.1: ¿Que es un sistema operativo?
Las clases de sistemas operativos en la que nos basáremos serán los denominador multiusuarios y de multiprogramación es decir que varios usuarios podrán correr concurrentemente múltiples programas.
Un SO es una parte importante de casi cualquier sistema informático. Para entender mejor esto veremos que un sistema informático puede separar en cuatro partes
- el hardware
- el SO
- los programas de aplicación
- los usuarios
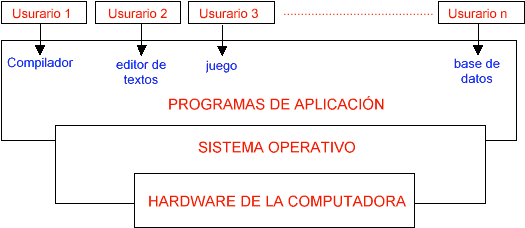
Estas partes hacen de capas, cada una de las cuales acerca mas al usuario a utilizar los recursos del hardware.
El Hardware (CPU, memoria y dispositivos) proporciona los recursos de computación básicos sobre los que se agregaran estas capas sucesivas.Los programas de aplicación como los compiladores, juegos, aplicaciones de negocios, definen la forma en que estos recursos se emplearan para solucionar los problemas del usuario.
Puede haber varias clases de usuarios usando el sistema(personas, programas y otras computadoras) tratando de resolver diversos problemas.El SO controla y coordina el uso del hardware entre los diversos programas de aplicación y los distintos usuarios. Administra todos los recursos como disco, memoria, impresoras, monitor, etc.
El SO determina los tiempos en que un determinado programa utilizara un recurso dado.
Al comienzo de la era informática, los sistemas no utilizaban SO's Estas computadoras de hace 40 años ejecutaban un programa a la ves que era cargado por un programador. Este cargaba el programa y lo ejecutaba. Si existía algún error que hiciera que le programa se detuviera antes de lo esperado, se tenia que comenzar de nuevo con todo el proceso.
Recordemos que en esa época no había muchas computadoras en funcionamiento, así que el programador tendría que esperar seguramente de varios días hasta que nuevamente tuviera su turno enfrente de la computadora de aquella época.
Los SO's existen porque son una manera razonable de solucionar el problema de crear un sistema informático utilizable. El objetivo fundamental de los sistemas informáticos es ejecutar los programas de los usuarios y facilitar la resolución de sus problemas. Todo esto se hacia a través de tarjetas perforadas que una persona encargada cargaba en la computadora y luego de algunas horas devolvía la salida impresa al programador.
Al avanzar la tecnología informática, muchos de estos programas se cargaban en una sola cinta, otro programa residente en la memoria de la computadora, cargaba y manipulaba los programas de esa cinta. Este es el ancestro de los SO's de hoy en día.
En la década del 60 la tecnología de SO's avanzo mucho y se podían tener múltiples programas al mismo tiempo en la memoria. Así surgió el concepto de multiprogramación. Si un programa necesitaba esperas a que ocurriera algún evento externo, como que una cinta se rebobinara, otro podría tener acceso a la CPU para así poder utilizar el 100 % del poder de procesamiento con que contaba la computadora. Esto ahorraba mucho dinero ya que en aquel entonces todo en lo referente a computo (memoria, espacio en disco, etc) costaba cientos de miles de dólares.
A finales de los 60's, en 1969, nació UNIX, SO que trataremos mas adelante, y es la base de muchos de los SO's de hoy en día, aunque muchos no lo admitan.Definir que forma parte de un SO y que no seria difícil, dada la gran variedad existente, pero una definición para los SO que nos compete en estos momentos seria que el SO es el programa que ejecuta todo el tiempo en la computadora (conocido usualmente como KERNEL o núcleo), siendo los programas de aplicación todo lo demás.
En general un SO intenta incrementar la productividad de un recurso de proceso tal como el hardware de la computadora, o de los usuarios de los sistemas informáticos.
Ahora bien en lo referente a la utilización eficiente de un sistema informático no siempre se puede lograr que un SO lo logre. Casi siempre resulta contradictorio la comodidad y la eficiencia.
1.2: Unix como base de sistemas operativos
Como dijimos antes, en 1969, algo maravilloso sucedió en el mundo de la informática; nació UNIX.
En principio como un trabajo solitario de Ken Thompson, de Bell Labs, y luego en conjunto con Dennis Ritchie y otros miembros del Bell Labs que se fueron incorporando.
Ritchie ya tenia experiencia dado que había trabajado en otro proyecto llamado MULTICS, el cual fue de gran influencia sobre el nuevo SO, como por ejemplo en la organización básica del sistema de archivos, la idea de un interprete de comando (el shell) como un proceso de usuario, etc.
La primera versión de UNIX estaba hecha íntegramente en ensamblador, lo que se cambio con la versión posterior que fue escrita en lenguaje C lo que lo hizo sumamente portable; así mismo también se le agrego una característica por demás de importante, la multiprogramación. Esto y la entrega de licencias gratuitas con fines educativos extendieron su uso, desarrollo y la investigación en las universidades.
El uso de UNIX se fue ampliando a medida que se le fueron adicionando herramientas de software y entornos de programación, apoyo a protocolos de red Internet (TCP/IP), mejoras en el editor de texto (VI), compiladores de C, PASCAL y LISP, mejora en el control de congestionamiento de redes y el rendimiento de TCP/IP.
Al crecer la popularidad de UNIX, se a transportado a distintas plataformas de hardware (PC, MAC, ALPHA) y se han creado una gran cantidad de SO's UNIX y parecidos a UNIX (XENIX de Microsoft, AIX de IBM, SOLARIS de SunSoft).Las características principales de este SO es que se diseño como un sistema de tiempo compartido es decir que los múltiples usuarios estarán usando el sistema sintiéndolo como que son los únicos que están trabajando en el, lo que logra el SO asignándole un tiempo de atención para el CPU a cada usuario.
La interfaz estándar con el usuario (el shell) puede ser cambiada si se quiere. La mayoría del código fuente original esta disponible por lo que los usuarios podrán ajustar el SO a sus requerimientos especifico.
Es multitarea (permite que se puedan ejecutar varios procesos al mismo tiempo compartiendo el uso de la CPU.
Soporta el procesamiento en tiempo real (ejecución de procesos en intervalos de tiempo especificados sin retardo), el cual se utiliza en aplicaciones de robótica y base de datos.
Los sistemas UNIX son esenciales para la Internet.
Los sistemas de archivos con árboles multiniveles permiten que el SO trate tanto a directorios y archivos como simples secuencias de byte's.
Posee distintos niveles de seguridad: password's de ingreso y permisos de archivos y directorios.
Un proceso puede fácilmente generar otro, también es posible el manejo de procesos en determinado tiempo. Puede planearse la utilización de la CPU.
El kernel y biblioteca del SO están preparados para un SO que pueda extenderse y crecer, lo que permitió a UNIX mantenerse siempre a la cabeza de los SO's estando permanentemente actualizado.
1.3: Procesos
Para poder entender bien el concepto de Proceso deberemos diferenciarlo en el lugar donde se encuentra. Un programa será un archivo cuando se encuentre en el disco rígido y será un proceso al encontrarse en memoria; de esta forma se comprenderá mejor que es un Proceso.
Pero también es cierto que un proceso es mucho mas que un programa en memoria y sobre todo en la clase de SO que nos compete, con sus funciones de multiusuario y multitarea como lo son los SO UNIX.
Cada programa cuenta con un conjunto de datos que usa para hacer su trabajo y en la mayoría de los casos estos datos no forman parte del programa.
Como ejemplo tomemos un programa de edición de textos. Los datos del archivos que el programa esta editando no forma parte del programa, pero si del proceso en memoria.
Si alguna otra persona utilizara al mismo tiempo el mismo procesador de texto que se encuentra en ese sistema, los dos estarían utilizando el mismo programa, pero no el mismo proceso. Ambas tendrían una copia para cada uno del proceso del editor de texto.
Así es que los programas podrán ser únicos para todos los usuarios, pero los procesos pertenecerán a cada usuario.
En UNIX varios usuarios podrán estar utilizando el sistema al mismo tiempo, esto se traduce a que el sistema tendrá múltiples procesos cargados en la memoria, y cada uno de ellos requerirá de la atención de la CPU en algún momento.
El sistema llevara un control de los procesos que están funcionando en ese momento, en que terminal y a que usuario pertenece además de otros datos. Todo ello estará apuntado en una "TABLA DE PROCESOS", en la cual el SO asignara el tiempo que tardara la CPU para atender cada proceso.
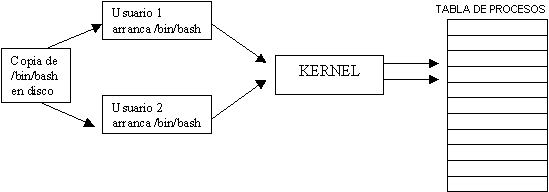
Cuando uno entra a un sistema UNIX, generalmente obtiene accesos a lo que se denomina "INTERPRETE DE COMANDOS". La gente que haya utilizado DOS sabrá que esto, ya que el C:> es el indicador de shell de su interprete de comando, el COMMAND.COM.
En un sistema UNIX el indicador será algo como $, # o %. Este shell es un proceso que esta corriendo y pertenece al usuario que esta corriéndolo en ese momento. En realidad es una copia del interprete de comandos que esta corriendo en memoria.
Al cargarse un programa desde el interprete de comando (SHELL), este no se va, sino que queda a la espera de algún otro mandato. Mientras tanto, para correr el programa, se crea un nuevo proceso, el del programa, que será hijo del proceso del shell.
Un proceso tiene un solo padre pero puede tener múltiples hijos.
Al iniciar una sesión en Linux tendrá un único será propietario de un único proceso, por ejemplo "/bin/bash" que es el interprete de comandos mas usados y el que usaremos nosotros.
Luego cada proceso que ejecute a partir del bash, se acomodara en el árbol de procesos como hijo del bash.
El bash permanecerá atento a que se le de un nuevo mandato, mientras tanto se dice que esta durmiendo.Como habíamos dicho antes, múltiples procesos podrán estar ejecutándose al mismo tiempo. Por ello se tendrá que asignar un tiempo a cada proceso para recibir la atención exclusiva la CPU. Es común que cada proceso tenga por 1/100 segundos la atención total de la CPU.
Esto dará la ilusión al usuario de que es el único que tiene la atención del sistema, pero que ocurriría si el proceso se colgase. En un sistema monousuario como el Windows (no el NT) esto seguramente ocasionaría el cuelgue del sistema ya que el Kernel no podría recuperarse dado que el proceso tiene control absoluto de la CPU. Esto no ocurre en Linux dado que todos los procesos responden al kernel y es el kernel quien les da permiso de usar la CPU en el momento necesario.Supongamos que queremos guardar nuestro trabajo del editor de textos. Entonces, y con la combinación de teclas correctas, le damos la orden al proceso del editor de textos para que guarde el trabajo. Esto, para nosotros, se hace instantáneamente pero es solo otra ilusión.
El proceso del editor de textos emite una petición al kernel para escritura del disco, el kernel entonces escribirá el disco en bloques, dependiendo de cuan libre este, mientras tanto guardara los datos en un espacio secundario de almacenamiento denominado cache. Esto es beneficioso por varias razones. En caso de que los datos que estemos escribiendo en ese momento sean requeridos un momento después, estos estarían disponibles en el cache y se ahorraría un viaje al disco. También seria beneficioso por el lado de la eficiencia del sistema, ya que escribirá al disco solo cuando el procesador este ocioso, no ocasionando con el proceso de escritura que el sistema funcionara mas lentamente.
Suponiendo que alguna otra persona necesitara en ese momento un dato del disco, el proceso de lectura tendría que esperar su turno, entonces es puesto a "dormir". El proceso tendrá que esperar a que se termine el tiempo asignado al proceso de escritura y luego se le despertara y podrá tomar su lugar para acceder al disco.
Exite también otro tipo de eventos en los que la CPU repara para poder detener a un proceso en curso, estos son las interrupciones.
Se ocasionan cuándo un dispositivo, léase mouse o teclado, requiere la atención de la CPU, es asi que se genera una interrupción que la CPU atenderá, mandando a dormir al proceso en curso.
Por supuesto hay mas complicaciones que las expuestas aquí, entre ellas las prioridades de los procesos que se verán cuando tomemos la parte de 6.7 de tareas y procesos.El tema de prioridades lo maneja el Kernel de acuerdo a varios aspectos, como el dueño del proceso, si es de sistema o no, etc.
Los procesos de sistemas son utilizados para la administración de memoria y la calendarización de turnos para la CPU. Estos procesos se los conoce como daemon (DEMONIOS) o programas servidores. Funcionan sin la intervención del usuario y sin que este los vea y hacen su trabajo esperando su turno cuando les llega para actuar.1.4: Archivos, directorios y diferencias
Definición:
Un archivo no es mas que un conjunto de bytes relacionados que están en disco u otro medio, a los que se les asigna un nombre que se utilizara para referirse a este archivo.
Un directorio no es mas que un archivos comunes a los que se les a impuesto una estructura particular.Esto tal ves llame la atención. En Linux y UNIX todo es archivo.
Si, todo es archivo. El teclado, el monitor, el disco rígido y hasta la memoria.
El SO trata a los dispositivos como archivos y de esa manera utiliza los mismos métodos de apertura, escritura, lectura y cierre para todos ellos.
La clase de archivos de los que estamos hablando se denomina archivo de dispositivo y es solo una de las clases de archivos que existen en Linux.
En DOS se acostumbraba a que solamente aquellos archivos con extensión .EXE . COM o .BAT se podían ejecutar. En Linux cualquier archivo puede llegar a ser ejecutable sin importar que extensión tengan. De cómo resulte la ejecución de un archivo que no tenia nada que ejecutar depende solamente de la aleatoriedad.
Esta clase de archivos ejecutables puede ser de dos clases también.
Aquellos que tienen lo que se denomina un numero mágico, el cual se encuentra en /etc/magic, y que determina el comportamiento del sistema cuando se ejecute, o que sea un scrip del shell, el cual será interpretado por el shell instrucción por instrucción como los archivos .bat del DOS.
Otro tipo de archivo es el de canalización. Esta clase de archivo sirve de canal donde los datos entran por un extremo y salen por el otro. Son creados por los procesos y desaparecen al morir el proceso, pero mientras tanto están ocupando un lugar físico en el disco. Cuando se trate el tema de Pipes y canalización se entrara mas en detalle.La forma en que se puede nombrar un archivo no esta limitada como en DOS a de 8 letras seguido de 3 caracteres de extensión.
Los nombres pueden ser de 255 caracteres de longitud y pueden tener puntos, guiones y demás símbolos como separadores. Los únicos nombres que no están permitidos son "/" y NULL, ya que "/" representa el directorio que es padre de todos los demás, el directorio raíz, y el NULL representa nada por ello no puede crearse algo que no es nada.nota.txt
nota.textual
nota.para.julio
nota_julio_hoySi trabajáramos en un sistema DOS solamente el primer archivo seria un archivo reconocido como texto, en cambio en Linux cualquier archivo de estos podrá contener texto.
Los archivos que llevan un punto inicial, ".nota.textual" son denominados archivos de punto y el SO los pondrá de manera predeterminada como ocultos.
Organizar los archivos en directorios es la forma más útil de trabajar con ellos. Aunque pareciera que los directorios contienen a los archivos, esto no es verdad. En realidad los archivos están asociados a ese directorio, y solo son mostrados como si estuviesen dentro de él.
La forma de referenciar un archivo es ir poniendo los nombres de los subdirectorios seguido por una "/". EJ. /home/seba/cartas/carta_nanci.
A esto se le denomina "ruta del archivo" y establece una ruta única para determinado archivo ya que podría existir otro archivo con el mismo nombre pero con una ruta diferente. Ej./home/nanci/carta_nanci
Pero no seria el mismo, sino otro. A lo sumo podría ser un enlace a la carta del directorio /home/seba/cartas, pero eso lo veremos luego.
Uno puede moverse de arriba abajo en un árbol de directorio por medio del comando CD (cambio de directorio) que forma parte del shell.-
El SO llevara cuenta del directorio en que estamos parados actualmente, denominado "directorio de trabajo", cuando uno cambia de directorio, el SO verifica esta parte de memoria y si es posible efectúa el cambio actualizándola con el directorio de trabajo actual. No importa si nos movemos arriba o abajo del directorio de trabajo, solamente esta información es la que cambia para que tengamos la ilusión de que nos estamos moviendo a través del árbol de directorios.
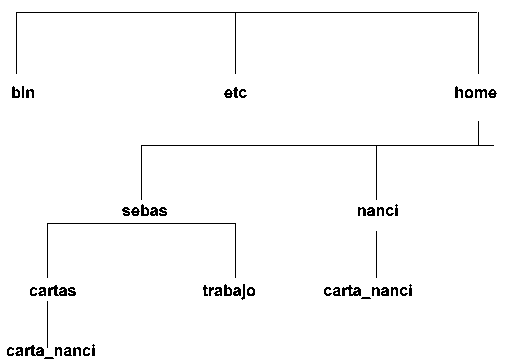
Los directorios tienen información que apunta hacia la ubicación de los archivos reales.
Esta información, tanto en los archivos y directorios y junto con el nombre del creador, tamaño permisos, etc, es guardada en lo que se denomina "TABLA DE INODOS"
Esta tabla se crea cuando se crea el sistema de archivos en Linux, comparable al formateo de una partición DOS. Se crea esta tabla que contendrá la mayoría de la información de los archivos.Entender lo que habíamos dicho en un principio de que "todo es archivo en Linux" puede resultar algo traumático, pero si vemos que esto resulta en un mejoramiento de cómo el sistema accede a sus recursos, vamos entendiendo que se establece una mayor sencillez.
Al ingresar al sistema se abrirán 3 archivos. La entrada estándar (stdin) la salida estándar (stdout) y el error estándar (stderr).
Cuando ingresamos datos por el teclado, estamos escribiendo en el archivo stdin y al verlos por la pantalla sé esta escribiendo el archivo stdout.
Si en algún punto existiera un error saldría por la pantalla, pero se estaría escribiendo el archivo stderr.
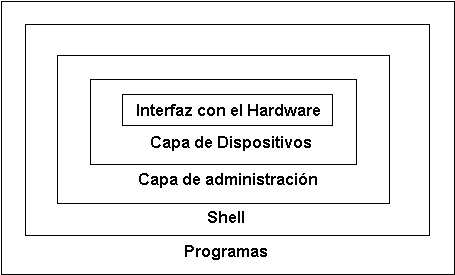
1.5: El sistema operativo en capasPodemos imaginar a Linux como una cebolla donde cada capa se comunica con la capa inferior.
En la parte del centro se encuentra la capa de comunicación con el hardware. El SO la utiliza para poder controlar los diversos aspectos del hardware. Sobre ella se encuentra la capa de dispositivos. Es un conjunto de funciones denominadas "controladores de dispositivo" que se encuentra dentro del kernel del SO. Ellas acceden directamente al hardware y hacen el trabajo de lectura, escritura, etc. Es un punto muy sensible del sistema en donde cuando un error surge poco puede hacerse para detener el proceso.
Sobre la capa de dispositivos se encuentra la capa de administración, esta es un conjunto de funciones a las que se hace referencia como sistema operativo tomando la decisión de que se ejecuta y cuando. Son las funciones que administran también los procesos, dándoles los turnos pertinentes y mandándolos a dormir cuando no es su turno.
La capa que sigue es la de los procesos mismos, por ejemplo el shell del SO. Estos procesos reciben la ordenes directamente del usuario u otros procesos y los traducen al lenguaje de maquina pasándoselos al SO para su ejecución.
A partir del shell se podrán arrancar otros procesos, como programas, que forman la capa superior de la cebolla. Estos se comunicaran con el shell para que el SO interprete sus ordenes.
Sebastian D. criado - seba_AT_lugro.org.ar
www.lugro.org.ar

